LLM backends¶
AuDesign Voice is backend-agnostic. The orchestrator wraps three concrete providers behind one streaming chat-completions interface, so your client and protocol stay identical no matter which model you run behind it.
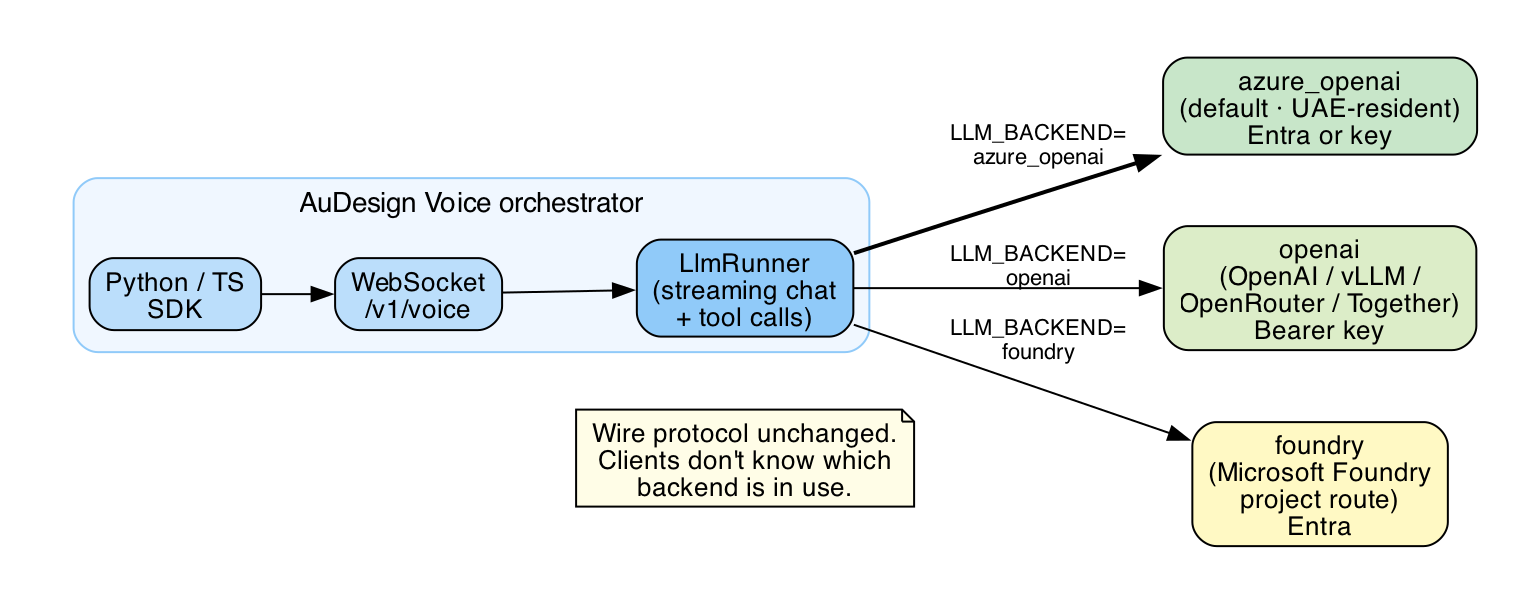
| Backend | When to use | Auth |
|---|---|---|
azure_openai |
Default. Azure OpenAI deployment (UAE North or other region). | Entra (DefaultAzureCredential) or API key |
openai |
OpenAI directly, or any OpenAI-compatible endpoint (vLLM, OpenRouter, Foundry serverless, Ollama with OpenAI-compat layer). | API key (Bearer) |
foundry |
A Microsoft Foundry project endpoint that exposes the OpenAI-compatible route. Lets you reuse Foundry's connections, RBAC, agent hosting, and observability. | Entra (DefaultAzureCredential) |
Switch with one env var: LLM_BACKEND.
Azure OpenAI (default — UAE-resident)¶
LLM_BACKEND=azure_openai
AZURE_OPENAI_ENDPOINT=https://your-aoai.cognitiveservices.azure.com/
AZURE_OPENAI_DEPLOYMENT=gpt-4.1 # name of the deployment, not the model
AZURE_OPENAI_API_VERSION=2024-10-21
# Leave AZURE_OPENAI_API_KEY empty to use Entra auth.
Required RBAC for Entra auth¶
Grant the orchestrator's identity (you locally; the App Service Managed Identity in production):
- Cognitive Services OpenAI User (or
Contributor) on the AI/OpenAI resource.
Models we recommend¶
| Model | Notes |
|---|---|
gpt-4.1 |
Best general voice quality. UAE North = GlobalStandard SKU only (data may leave region). |
gpt-4o-mini |
Cheaper. Lower latency. Good for FAQs. |
gpt-5-mini |
Newer reasoning. Slightly higher latency. EU regions. |
OpenAI (or any OpenAI-compatible endpoint)¶
LLM_BACKEND=openai
OPENAI_API_KEY=sk-…
OPENAI_BASE_URL=https://api.openai.com/v1
OPENAI_MODEL=gpt-4o-mini
Works with anything that speaks POST /chat/completions with stream=true and OpenAI tool-call schema:
| Provider | OPENAI_BASE_URL |
|---|---|
| OpenAI | https://api.openai.com/v1 |
| OpenRouter | https://openrouter.ai/api/v1 |
| Together AI | https://api.together.xyz/v1 |
| vLLM (self-hosted) | http://your-vllm:8000/v1 |
| Foundry serverless model | https://<endpoint>.services.ai.azure.com/openai/v1 |
⚠️ Once you point at a non-Microsoft endpoint, your audio transcripts will leave Microsoft's data plane. Document that in your privacy notice.
Microsoft Foundry project¶
When your team manages models, agents, knowledge, and observability inside a Foundry project, point AuDesign Voice at the project's OpenAI-compatible route. You keep Foundry's connections, content filters, and RBAC; AuDesign Voice just adds the voice surface.
LLM_BACKEND=foundry
FOUNDRY_PROJECT_ENDPOINT=https://your-project.services.ai.azure.com
FOUNDRY_MODEL=gpt-4o # or gpt-4.1, gpt-5-mini, etc — must be deployed in the project
Authenticated via Entra (DefaultAzureCredential). Grant the orchestrator's identity Azure AI User on the Foundry project.
Tools and knowledge¶
Function tools you declare via session.update.tools flow through unchanged. If you want to use a Foundry hosted tool (Bing search, code interpreter, file search, hosted MCP, etc.), you have two options:
- Wrap a Foundry agent as the LLM. Use Agent Framework or
AIProjectClient.AsAIAgent(...)to build an agent that has those tools, then expose it through AuDesign Voice as a function tool with one parameter (query). See Agent Framework integration. - Call them yourself server-side from the orchestrator (advanced; modify
apps/orchestrator/audvoice/llm.py).
Per-session override¶
Clients can override the model per session without restarting the service:
The model name must be valid for whichever backend is configured (e.g. a deployment name for azure_openai, an OpenAI model id for openai, a Foundry deployment name for foundry).
Latency notes¶
End-to-end voice round-trip (user stops → first audio out) varies with backend:
| Backend | Typical p50 |
|---|---|
| Azure OpenAI (UAE North) | 700–900 ms |
| Azure OpenAI (Sweden Central) | 500–700 ms |
| OpenAI (US) | 600–900 ms |
| Foundry (same region) | 700–1000 ms |
Measured with gpt-4o-mini, 16 kHz STT, 24 kHz TTS, single-sentence reply.